Concurrency in Kotlin Server-Side Development

[ad_1]
Imagine you’re running a bustling restaurant. Orders fly in, dishes need cooking, tables require clearing, and happy customers demand attention. How can you handle all this chaos without everything turning into a total disaster? This is where concurrency comes in.
In the world of server-side development, things can get just as hectic. Users fire off requests, databases need querying, calculations demand crunching, and all this needs to happen smoothly and efficiently. Without concurrency, it’s like having one overworked chef trying to do everything.
But with concurrency, it’s like adding a whole team of skilled multitaskers to your kitchen. You have specialized “coroutines” handling different tasks – one taking orders, another cooking, one washing dishes, and so on. Each works simultaneously, but in a coordinated way, ensuring your customers get their delicious meals fast and with a smile.
Examples of Concurrency
Here are some real-world examples of how concurrency works in server-side development:
Serving multiple users at once: Imagine your website gets slammed by eager shoppers during a flash sale. Without concurrency, each user request would have to wait its turn, leading to frustratingly slow loading times.
But with coroutines, multiple requests can be processed simultaneously, keeping everyone happy and shopping with ease.
Processing data pipelines: Do you work with really large datasets? Concurrency can break them down and analyze them bit by bit.
Handling asynchronous requests: Think of API calls, database queries, or file uploads. These often take time to complete. With concurrency, your main program doesn’t have to sit and wait. It can launch separate coroutines to handle these requests and get back to other tasks, keeping everything running smoothly.
Concurrency isn’t just some fancy buzzword – it’s a powerful tool that lets you handle the ever-growing demands of server-side development with ease and efficiency.
Now, we’ll dive deeper into the differences between threads and coroutines, the fundamental building blocks of concurrent programming in Kotlin.
Threads vs. Coroutines
Now, let’s talk about the two main players on this team: threads and coroutines.
What are Threads?
Threads are powerful, and capable of handling complex tasks – but they’re also a bit resource-hungry. Each thread requires its memory space and attention from the operating system.
This can be great for demanding tasks like breaking down big numbers or sending critical emails, but if you have too many threads running around, your server starts getting overwhelmed, leading to slowdowns and even crashes.
What are Coroutines?
Coroutines are lightweight, flexible, and able to switch between tasks in a flash. They don’t need their dedicated tables, they share resources efficiently, and they can even pause their work gracefully if something else needs immediate attention.
Think of them as taking orders, checking on tables, and cleaning dishes – always contributing, but in a light and adaptable way.
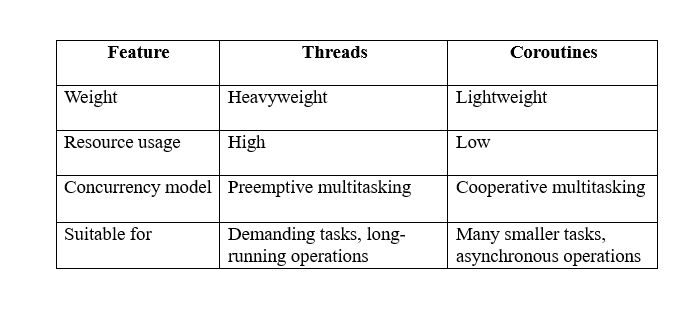
So, which of them should you choose? Well, it depends! For heavy lifting, threads are strong and reliable. But for the everyday hustle and bustle, coroutines are your agile friends.
Kotlin favours coroutines for concurrent programming because they’re more efficient and easier to manage, especially when dealing with lots of asynchronous tasks.
How to Launch Coroutines
In your server-side code, there are two main ways to launch coroutines.
Launch and Forget: Using the launch Keyword
This fires up a new coroutine and sends it off to its assigned task, but doesn’t wait for it to finish.
Here’s how it looks in code:
fun updateCustomerOrder(
orderId: Int,
newDish: String
) {
launch {
updateOrderInDatabase(orderId, newDish)
}
sendConfirmationEmail(orderId)
}This is ideal for tasks that don’t need immediate feedback. You can launch multiple coroutines like this without overloading your server, as they work independently and share resources efficiently.
Wait and Receive: The async Keyword
Now, let’s say you need to know the total bill before you can settle up with the customer. This is where async comes in. It’s like sending an assistant to calculate the bill and then patiently waiting for them to return with the answer.
Here’s how it works:
fun calculateBill(orderId: Int): Double {
val billResult = async {
calculateBillFromDatabase(orderId)
}
val totalBill = billResult.await()
return totalBill
}This is useful for tasks where you need the result before proceeding. The async keyword creates a coroutine that calculates the bill in the background (performs the task), but the main program pauses and waits until the result is ready.
Channels: Communication Lifelines
Channels allow coroutines to send and receive messages in a safe and organized way, even when things get crazy. Here’s how they work:
One-Way Streets: Send Channels
A send channel allows one coroutine to send a message that another coroutine can receive on the other end. Only one direction, just like a one-way street.
Bi-Directional Bridges: Receive Channels
Receive channels allow a coroutine to wait for and receive a message that was sent on the corresponding send channel. Two-way communication, like a bridge in both directions.
Putting Channels to Work:
Here’s an example of using channels to update customer orders:
val orderUpdatesChannel = Channel<Pair<Int, String>>()
fun updateCustomerOrder(orderId: Int, newDish: String) {
launch {
updateOrderInDatabase(orderId, newDish)
orderUpdatesChannel.send(orderId to newDish)
}
}
fun sendOrderConfirmationEmails() {
while (true) {
val orderUpdate = orderUpdatesChannel.receive()
val (updatedOrderId, newDish) = orderUpdate
sendConfirmationEmail(updatedOrderId)
}
}In this case, the updateCustomerOrder coroutine sends the updated order details through the orderUpdatesChannel. The sendOrderConfirmationEmails coroutine constantly waits on the channel, receiving updates one by one and sending out confirmation emails.
Structured Concurrency
Think of structured concurrency like assigning roles and responsibilities in your kitchen. It helps you:
- Define the scope: You can create coroutine contexts that provide specific resources and boundaries for your coroutines to work within. This keeps things organized and prevents rogue coroutines from mucking up the system.
- Cancellation: Imagine a customer changing their order halfway through cooking. Structured concurrency allows you to easily cancel the wrong dish and start preparing the new one, without everything crumbling into a greasy mess.
- Supervision: Structured concurrency lets you set up supervisors who monitor their “child” coroutines, ensuring they finish their tasks properly or handle errors gracefully.
Key tools for structured concurrency:
Dispatchers: They control where and how your coroutines run, like assigning them to specific threads or pools.
Jobs: Think of them as the tasks themselves, assigned to specific coroutines within a context. You can track their progress, cancel them if needed, and keep things organized.
Supervisor Jobs: They supervise child jobs, handling failures and propagating them properly, preventing errors from cascading and ruining the whole meal.
Different types of tasks in your server-side code demand different environments. This is where the various dispatcher types come in:
- The Main Dispatcher: Think of it as the front of the house, handling UI updates and interacting directly with the customer (user). It’s a single thread, ensuring smooth and responsive interactions without any chaotic multitasking.
- The Default Dispatcher: This is the workhorse for general computation tasks. It uses a thread pool, assigning coroutines to available threads. Great for CPU-intensive calculations, database processing, and other heavy lifting.
- The IO Dispatcher: This dispatcher handles blocking I/O operations like network calls, file access, or database queries.
- Custom Dispatchers: You can create custom dispatchers with specific thread pools or even single threads, tailoring them to the needs of your unique tasks.
Choosing the right dispatcher is very important for optimizing performance and avoiding congestion. Here are some tips:
- Use the main dispatcher only for UI updates and user interaction.
- Default dispatcher for most CPU-intensive tasks.
- IO dispatcher for any blocking I/O operations.
- Consider custom dispatchers for specific high-volume or sensitive tasks.
Flows
Imagine your restaurant is booming, orders flying in faster than the chefs can cook. How do you handle this data deluge without everything turning into a soggy mess?
Think of Flows as streams of data flowing through your server-side code, like the continuous stream of orders coming from the tables. Instead of dealing with each dish individually, Flows let you handle the data continuously, adapting to the pace and transforming it on the fly.
Here’s why Flows are a game-changer:
- No more waiting around for data to arrive. Flows let you launch coroutines to handle the stream asynchronously, keeping your main program free to keep taking orders and managing the overall experience.
- Flows allow you to extract insights, generate reports, or trigger actions in real-time.
- Flows automatically adjust their pace based on downstream processing capabilities, preventing backlogs and ensuring smooth data flow through your system.
- Errors are handled delicately with flows, which transmit them without bringing down the entire service.
Here’s an example of using Flows to process a stream of sensor readings:
val sensorReadingsFlow = sensorManager.readings()
.filter { reading -> reading.temperature > 80 }
.map { reading -> "Alert! Sensor ${reading.id} at ${reading.temperature} degrees!" }
.launchIn(Dispatchers.IO)
.onEach { message -> logger.warn(message) }
.collectLatest { message -> sendPushNotification(message) }This Flow reads sensor readings continuously, filters for high temperatures, transforms them into alert messages, and sends them to users, all in a non-blocking, resilient way.
Flows are a powerful tool for modern server-side development. They let you embrace the world of asynchronous data processing with grace and efficiency, keeping your code responsive, scalable, and ready to handle whatever data banquet your users throw at you.
Testing Your Concurrency Setup
So, you’ve built your server-side kitchen with agile coroutines, smooth communication channels, and efficient dispatchers. Your data flows like a rushing stream, and your customers (users) are singing your praises. But before you hang the “Open” sign permanently, there’s one more crucial step: testing your concurrency magic.
Testing helps you uncover edge cases, prevent crashes, and ensure everything runs smoothly even under heavy load.
Here are some key points for testing concurrent code:
- Focus on isolation: Test individual coroutines and channels in isolation to identify problems in specific components. You can use libraries like kotlinx-coroutines-test to control time and simulate asynchronous behavior.
- Mock dependencies: External dependencies like databases or APIs can add complexity. Mocking these dependencies allows you to focus on coroutine behavior without introducing real-world uncertainties.
- Verify state changes: Ensure coroutines update data structures and flags correctly as they execute. Assert expected values at different points in the execution flow.
- Stress test performance: Push your code to its limits with high volume or complex scenarios. This helps you identify bottlenecks and ensure your system scales gracefully.
Remember, testing concurrent code is not always straightforward. Be patient, experiment with different methods, and don’t be afraid to seek help from experienced developers and testing frameworks.
Conclusion
We’ve explored agile coroutines dancing across tasks, efficient channels keeping them in sync, and smart dispatchers directing the flow. We’ve seen how Flows seamlessly handle data streams, and we’ve learned the importance of robust testing to ensure everything runs smoothly.
Now, with this knowledge, you should understand the concept of concurrency in your Kotlin applications. Embrace it, use it wisely, and watch your applications soar to new heights of responsiveness, scalability, and efficiency.
[ad_2]
Source link