A How to Start a Career in Site Reliability Engineering – SRE Career Guide

[ad_1]
If you’re considering a career in the Site Reliability Engineering (SRE) field, you should understand what SREs do, how to get started, and how to grow as an SRE.
In this article, we’ll explore what you need to know to be an SRE, and how you can develop your skills to become a successful one.
Here’s what we’ll cover in this article:
- Introduction to Site Reliability Engineering
- Role and Responsibilities of an SRE
- Importance of SRE in Modern Tech Organizations
- Prerequisites and Fundamental Knowledge
- Essential Skills for SRE
- Learning Path and Resources
- How to Succeed in the SRE Field
- Conclusion
Before we get started…
This isn’t a course or a complete tutorial on how to master SRE – that is, it doesn’t teach all the nitty-gritty of SRE. Instead, it’s more like a guide that’ll walk you through how to become an SRE by providing the needed materials for you to succeed.
To get started with reading this guide, you should have a desire to learn and become an SRE. SRE is a wide field, and I urge you to have a burning zeal to learn and master it.
Last but not least, keep in mind that the linked resources and additional pointers contained in this post are my personal recommendations that should help you as you dive into the SRE field. Just make sure you chose the ones that best match your learning style and goals.
Introduction to Site Reliability Engineering (SRE)
The concept of Site Reliability Engineering (SRE) originated at Google in the early 2000s, emerging as a novel approach to tackling large-scale system management challenges.
SRE was born from the necessity to ensure the reliability and scalability of rapidly growing online services. And it has since evolved into a critical discipline within the tech industry.
This origin story not only highlights SRE’s roots but also its foundational importance in shaping modern operational practices.
In the early days of Google, the explosive growth of its services and the scale at which they operated introduced unprecedented reliability and scalability challenges.
Traditional IT operations approaches were insufficient for the company’s needs, prompting a rethink of how to manage large-scale systems efficiently and reliably. Google’s innovative solution was to create a new role that blended software engineering with IT operations, thus giving birth to Site Reliability Engineering.
This new breed of engineers was tasked with making Google’s already large and complex systems more reliable, efficient, and scalable. They applied software engineering principles and practices to infrastructure and operations problems, automating tasks that were traditionally performed manually.
This approach not only improved system reliability and efficiency but also allowed for scaling operations in a way that could keep up with the company’s rapid growth.
Definition and Purpose of SRE
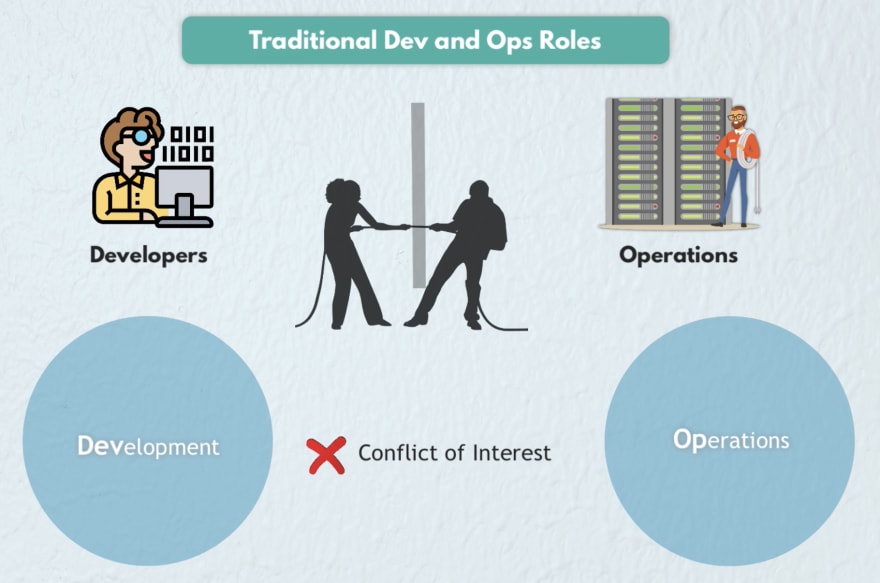
Photo Credit: TechWorld with Nana
After exploring its origins, you can see that SRE is fundamentally about applying a software engineering mindset to help solve operations problems.
At its core, SRE is about engineering resilience into systems and applications. It focuses on the intersection of software engineering and system administration, applying principles of software design to infrastructure and operations problems.
SRE aims to strike a balance between innovation and reliability, enabling organizations to deliver feature-rich products while maintaining high levels of service reliability.
The primary purpose of SRE is to build and maintain highly reliable, scalable, and efficient systems through a combination of software development, automation, and operational best practices.
By adopting a proactive and engineering-driven approach to operations, SRE teams strive to minimize service disruptions, mitigate risks, and optimize system performance.
Role and Responsibilities of an SRE
The role of an SRE is multifaceted, encompassing a wide range of responsibilities across software development, operations, and system architecture.
Some key responsibilities of an SRE include:
- Service Reliability: Ensuring the reliability, availability, and performance of critical services and systems.
- Automation and Tooling: Developing automation tools and systems for provisioning, deployment, monitoring, and incident response.
- Capacity Planning: Analyzing resource usage patterns and forecasting capacity requirements to support business growth.
- Incident Management: Responding to and resolving incidents in a timely manner, and conducting post-incident reviews to identify root causes and prevent recurrence.
- Performance Optimization: Identifying and addressing performance bottlenecks to improve system scalability and efficiency.
- Security and Compliance: Implementing security best practices and ensuring compliance with regulatory requirements to protect sensitive data and infrastructure.
- Collaboration and Communication: Working closely with cross-functional teams, including software engineers, product managers, and system administrators, to drive continuous improvement and innovation.
Importance of SRE in Modern Tech Organizations:
In today’s digital economy, where user expectations are higher than ever, the reliability and performance of online services are critical to business success. Downtime or poor performance can have significant financial and reputational consequences, leading to lost revenue, customer churn, and damage to brand reputation.
SRE plays a vital role in addressing these challenges by applying software engineering principles to infrastructure and operations. This improves system reliability, scalability, and efficiency.
By fostering a culture of reliability and resilience, SRE enables organizations to deliver better user experiences, reduce operational overhead, and drive business growth.
And as organizations increasingly rely on cloud computing, microservices architecture, and DevOps practices to innovate and scale their operations, the role of SRE becomes even more crucial. SRE provides the expertise and tools necessary to manage complex distributed systems effectively, enabling organizations to leverage technology to achieve their business objectives.
So as you can see, SRE is not just a technical discipline but a strategic imperative for modern tech organizations seeking to thrive in a highly competitive and dynamic market landscape. By investing in SRE principles and practices, organizations can build more resilient and reliable systems, driving innovation, growth, and customer satisfaction.
Prerequisites and Fundamental Knowledge
If you’re going to embark on a career in Site Reliability Engineering (SRE), you’ll need a solid foundation in computer science principles, a good grasp of programming, and an understanding of version control systems.
These components equip aspiring SREs with the necessary tools to design, develop, and manage reliable and scalable systems.
Understanding of Computer Science Basics
Operating Systems Concepts: A deep understanding of operating systems (OS) is crucial for SREs. This knowledge includes, but is not limited to, process management, memory management, file systems, and the OS’s role in defining the interactions between hardware and software.
🔗You can checkout this Handbook that teaches you key OS concepts for Mac, Linux, and Windows.
Familiarity with these concepts helps SREs in optimizing system performance and in diagnosing and troubleshooting system-level issues.
Networking Fundamentals: Networking is the backbone of the internet and cloud services, making it essential for SREs to understand the basics of networking. This includes 🔗TCP/IP models, DNS, HTTP, HTTPS, and network protocols, as well as the ability to diagnose network-related issues.
Here’s a 🔗solid introduction to computer networking basics you can use to get started.
And here’s a 🔗full handbook on HTTP Networking for beginners.
A solid grasp of networking principles allows SREs to ensure that the services they manage can communicate efficiently and reliably across the internet and within distributed systems.
Proficiency in Programming Languages
Recommended Languages (Python, Go, Java): SREs must be proficient in at least one programming language.
Python is widely favored for its simplicity and the vast ecosystem of libraries, making it ideal for automation scripts and tools.
freeCodeCamp 🔗has a couple Python certifications if you want to learn the basics and get some practice coding in Python.
Go, developed by Google, is becoming increasingly popular in cloud services and systems programming due to its efficiency and performance.
🔗Here’s a full course that’ll teach you go by having you build 11 projects.
Java, known for its portability and extensive use in enterprise environments, is also valuable.
🔗Here’s a full course that teaches you coding in Java, 🔗along with a handbook to reinforce your skills.
Mastery of these languages enables SREs to write efficient, reliable software that automates and enhances system operations.
Scripting Skills (for example, Shell Scripting): Scripting skills are important for automating routine tasks, such as software deployment, system configuration, and monitoring. Shell scripting, in particular, is essential for Unix/Linux-based systems.
🔗Here’s a tutorial on bash scripting that’ll walk you through some examples.
These scripting skills save time, reduce the likelihood of human error, and ensure that operations can scale efficiently.
Familiarity with Version Control Systems (like Git)
Version control is fundamental to modern software development and operations. Git, being the most widely used version control system, is crucial for tracking changes in code, collaboration, and maintaining the integrity of software projects.
Understanding Git workflows, branches, commits, and merges is essential for SREs, as it enables them to manage code changes, automate parts of the software delivery pipeline, and roll back changes if necessary.
🔗Here’s a full book that’ll teach you everything you need to know (and more!) to get started with Git.
And 🔗here’s a handbook that’ll review the common commands and actions you’ll use in version control every day.
Together, these prerequisites form the foundation upon which SREs build their skills. Mastery of computer science fundamentals, programming, and version control is essential for anyone looking to succeed in the rapidly evolving field of Site Reliability Engineering.
Essential Skills for SRE

The image above is gotten from SquadCast
The realm of Site Reliability Engineering is both broad and deep. It encompasses a range of skills that ensure systems are not only reliable but also efficient, scalable, and responsive to the needs of users and businesses alike.
System Administration and Operations
- Knowledge of Linux/Unix Administration: Proficiency in managing and troubleshooting 🔗Linux or Unix-based environments is fundamental. This includes managing file systems, users, processes, packages, and services.
- Network Administration: Understanding network configuration, firewall management, and network services ensures SREs can optimize network performance and security. 🔗Here’s an article that explains Network Admin.
- Resource Management: Efficient management of system resources, including CPU, memory, and disk IO, to ensure optimal performance and reliability.
Automation and Infrastructure as Code (IaC)
- Automation Tools: Proficiency in tools like Ansible, Chef, or Puppet for 🔗automating deployment, configuration, and management tasks.
- Infrastructure as Code: Using tools such as Terraform and CloudFormation to manage infrastructure through code, enabling scalable and reproducible environments with reduced human error. TerraForm is the most suitable and popular, and I recommend that you 🔗check out this 15 minute intro.
- Scripting and Coding: Ability to write scripts and small programs to automate tasks and integrate systems
Monitoring and Alerting
- Implementing Monitoring Tools: Experience with tools like 🔗Prometheus, 🔗Grafana, ELK Stack, or Splunk for real-time monitoring of applications and infrastructure. There are a lot of tools to mange and monitor incidents, but the ones listed above are the most wildly used in the industry.
- Log Management and Analysis: Ability to aggregate, analyze, and interpret logs from various sources for insight into system behavior and troubleshooting.
- Alerting Strategies: Developing effective alerting mechanisms that accurately reflect system health and operational issues without overwhelming with false positives.
Incident Response and Post-Incident Analysis
- Incident Management: Ability to lead and manage the response to system outages or performance degradations to restore service as quickly as possible.
- 🔗 Blameless Postmortems: Conducting thorough analysis post-incident to identify root causes without attributing blame, focusing instead on learning and improvement.
- Reliability Metrics: Tracking and improving key reliability metrics such as availability, latency, and error rates. 🔗 Here’s an article from Blameless that explains more about reliability metrics.
Capacity Planning and Performance Management
- Performance Tuning: After you’ve reviewed and gathered logs from your monitoring tools, it’s a good idea to identify and optimise performance bottlenecks in applications and infrastructure.
- Scalability Strategies: Planning and implementing strategies for scaling systems to handle growth in users or data volume efficiently.
- Capacity Forecasting: Using metrics and trends to forecast future capacity needs and planning ahead to meet those requirements. Don’t wait and hope the application won’t go down – your task is to see into the future with the tools and skills you have to prevent it from going down.
Cloud Computing Concepts and Technologies
- Cloud Service Models: Understanding the spectrum of cloud services (🔗 IaaS, PaaS, SaaS) and how they can be leveraged for reliability and scalability.
- Cloud Providers: Familiarity with major cloud providers such as AWS, Google Cloud, and Azure, and their specific technologies and services.
🔗 Here’s a 14 hour course to help you learn AWS, 🔗 a 4 hour course on Google Cloud, and a 🔗 13 hour course on Azure to get you on your feet! - Cloud-Native Technologies: Knowledge of cloud-native technologies and practices, including 🔗 microservices architecture, containers (for example, Docker), and orchestration tools (for example, 🔗 Kubernetes), to build and manage scalable, resilient systems. 🔗 This course teaches you both Docker and Kubernetes basics.
While all of these skills are vital, it isn’t a must to master them, especially all at once. But knowing or having basic understanding of these essential skills enables SREs to ensure that systems are not just up and running, but also optimised for performance, ready to scale as needed, and resilient in the face of failures.
The role of an SRE demands a blend of expertise in software engineering and system operations, making it both a challenging and rewarding career path.
Learning Path and Resources
Like I said earlier in this article, this isn’t a tutorial – it’s more like a learning path that’ll walk you through all that you need to get started in the SRE field.
The journey to becoming a proficient SRE is continuous and multifaceted. Engaging with a variety of resources and communities can significantly enhance your learning experience.
Below are some approaches and resources that you can use to learn or master the SRE field.
Online Courses and Tutorials
- Platforms like Udemy, Coursera, Udacity, and edX offer comprehensive courses on SRE fundamentals, 🔗 cloud computing, 🔗 automation, and more. Look for courses developed in partnership with leading tech companies and universities.
- Specific Tutorials on tools and technologies (for example, 🔗 Kubernetes, 🔗 Terraform, Prometheus) abound on YouTube, or through the documentation and learning resources provided by the tools themselves. 🔗 Here’s a fun tutorial that uses Prometheus as part of a larger tech stack to secure server infrastructure clouds.
Books and Publications
- 🔗 Site Reliability Engineering by Niall Richard Murphy, Betsy Beyer, Chris Jones, and Jennifer Petoff (often referred to as the “SRE Bible”), published by O’Reilly, offers insights directly from Google’s SRE team.
- 🔗 The Phoenix Project and 🔗 The DevOps Handbook by Gene Kim, Jez Humble, and others provide excellent insights into DevOps principles, which overlap significantly with SRE practices. If you’re a fan of books, then you can purchase those books to read.
- Industry Publications such as ACM Queue or 🔗 IEEE Software regularly feature articles on SRE topics, case studies, and best practices.
Hands-On Projects and Exercises
- Cloud Platforms offer free tiers or trial periods that are perfect for experimenting with cloud-based infrastructure and services.
- GitHub and GitLab host a multitude of open-source projects where you can contribute code, documentation, or even participate in issue resolution and feature requests.
- Personal Projects can also serve as a valuable learning tool. Try to replicate real-world systems, or automate the deployment and management of an application from scratch. The best way to learn is to practice.
- Contributing to open-source projects related to SRE tools and technologies not only gives you hands-on experience but also helps you understand the community standards and practices. Open source is a great way to learn from others, improve your knowledge, and gain valuable experience. Think of working on an open source project like an entry-level job where you get to do real things! Contribute, contribute, contribute.
Embarking on your SRE learning journey is both exciting and demanding. It requires a commitment to continuous learning and improvement.
Leveraging a mix of online resources, books, hands-on projects, community participation, and professional networking will equip aspiring SREs with the knowledge, skills, and insights needed to succeed in this dynamic field.
How to Succeed in the SRE Field
Navigating a successful career in Site Reliability Engineering (SRE) requires more than just technical acumen. You’ll also need to cultivate a mindset geared towards growth, collaboration, and resilience.
Achieving success as an SRE involves a blend of continuous learning, adaptability, communication, problem-solving, and a commitment to fostering a culture of reliability.
Continual Learning and Skill Development
- Stay Updated: The tech field evolves rapidly, with new tools, languages, and practices emerging constantly. Dedicate time regularly to learn new skills and technologies. Search through YouTube, LinkedIn and Twitter and connects with friends, folks and people who share the same goal and skills with you.
- Deepen and Broaden Your Knowledge: While specializing in certain areas is valuable, having a broad understanding of related disciplines, such as cloud services, networking, and cybersecurity, can significantly enhance your effectiveness as an SRE.
Adaptability to New Technologies and Methodologies
- Be Open to Change: Embrace new methodologies and technologies. The willingness to adapt and experiment with innovative solutions is crucial in an environment where reliability and efficiency are paramount.
- Experimentation and Evaluation: Apply critical thinking to assess the applicability of new tools and practices to your organization’s specific challenges and objectives.
Effective Communication and Collaboration
Problem-Solving and Troubleshooting Skills
- Analytical Approach: Develop a methodical approach to troubleshooting and problem-solving. This includes breaking down complex systems into smaller components, identifying potential failure points, and systematically eliminating possibilities.
- Learning from Failures: Adopt a mindset that views failures as learning opportunities. Conduct blameless postmortems to understand what went wrong and how similar incidents can be prevented in the future.
Embracing a Culture of Reliability and Resilience
- Prioritize Reliability: Advocate for reliability and uptime within your organization, emphasizing that reliability is a feature not just for customers but for the business’s bottom line.
- Resilience Engineering: Focus on building systems that are not only reliable under normal conditions but can also gracefully handle unexpected stressors and failures. This involves designing for failure, anticipating bottlenecks, and implementing fallback mechanisms. 🔗 Check out this article to learn more about Resilience Engineering.
Success in the SRE field is about more than just keeping the systems running. You’ll also need to foresee potential issues, enhance system resilience, and ensure that the infrastructure can support the organization’s long-term goals.
By focusing on continual learning, adaptability, communication, problem-solving, and a culture of reliability, you can contribute significantly to your team and organization, while also advancing your career in this dynamic and critical field.
If for some reasons you’re still lost in this SRE thing, you can connect with me on LinkedIn or Twitter where I’ll be sharing some news, info, and updates about trending SRE topics and discussions.
Conclusion
In this guide, we’ve journeyed through the essentials of what it takes to embark on a career in SRE. You should now understand its foundational principles and know how to acquire the necessary skills to excel in the role and make a significant impact within tech organizations.
Here’s a recap of what we covered:
Key Points
- Introduction to SRE: We started with the genesis of SRE at Google, outlining its purpose to bridge the gap between development and operations, emphasizing reliability, scalability, and operational efficiency.
- Prerequisites and Fundamental Knowledge: A strong foundation in computer science principles, programming languages, and version control is essential for aspiring SREs.
- Essential Skills for SRE: We delved into system administration, automation, monitoring, incident response, and cloud computing as critical skills for anyone in the SRE domain.
- Learning Path and Resources: The path to becoming an SRE involves continuous learning through online courses, books, hands-on projects, and community engagement.
- Succeeding in the SRE Field: Success hinges on continual learning, adaptability, effective communication, problem-solving skills, and fostering a culture of reliability and resilience.
Pursue SRE as a Career Path
Site Reliability Engineering is a mindset and a set of practices that can lead to highly rewarding careers. As businesses increasingly rely on technology, the demand for people who can ensure systems are reliable, scalable, and efficient has never been higher.
Pursuing a career in SRE offers the opportunity to work at the forefront of technology innovation, solving complex problems and making a tangible impact on the digital landscape.
[ad_2]
Source link