
Software Deployment Models – Explained for Beginners

[ad_1]
To effectively plan – or even talk about – application development intelligently, you usually have to understand which of the many program architectures you’re referring to. In other words, software code can be deployed in many more ways than just the “standard” web app.
So let’s see what we’ve got. There’s client/server computing, thin and fat clients, microservices, and various flavors of Application Programming Interfaces (APIs). Let’s explore these one at a time.
This article comes from my Complete LPI Open Source Essentials Exam Study Guide Udemy course and book. You can also view the video version of the article on YouTube.
Client/Server Architectures
Client/server computing architectures are a type of distributed computing architecture in which computing tasks are split between two types of machines: clients and servers.
A client is a device or program that requests services or resources from a server. Clients can be desktop computers, laptops, mobile devices, or any other device capable of making requests over a network.
A server is a device or program that provides services or resources to clients. Servers can be dedicated machines or programs that run on shared machines. Servers are responsible for processing requests from clients and returning the requested data or service.
The interaction between clients and servers is typically based on a request-response model. A client sends a request to a server over a network, and the server processes the request and sends a response back to the client.
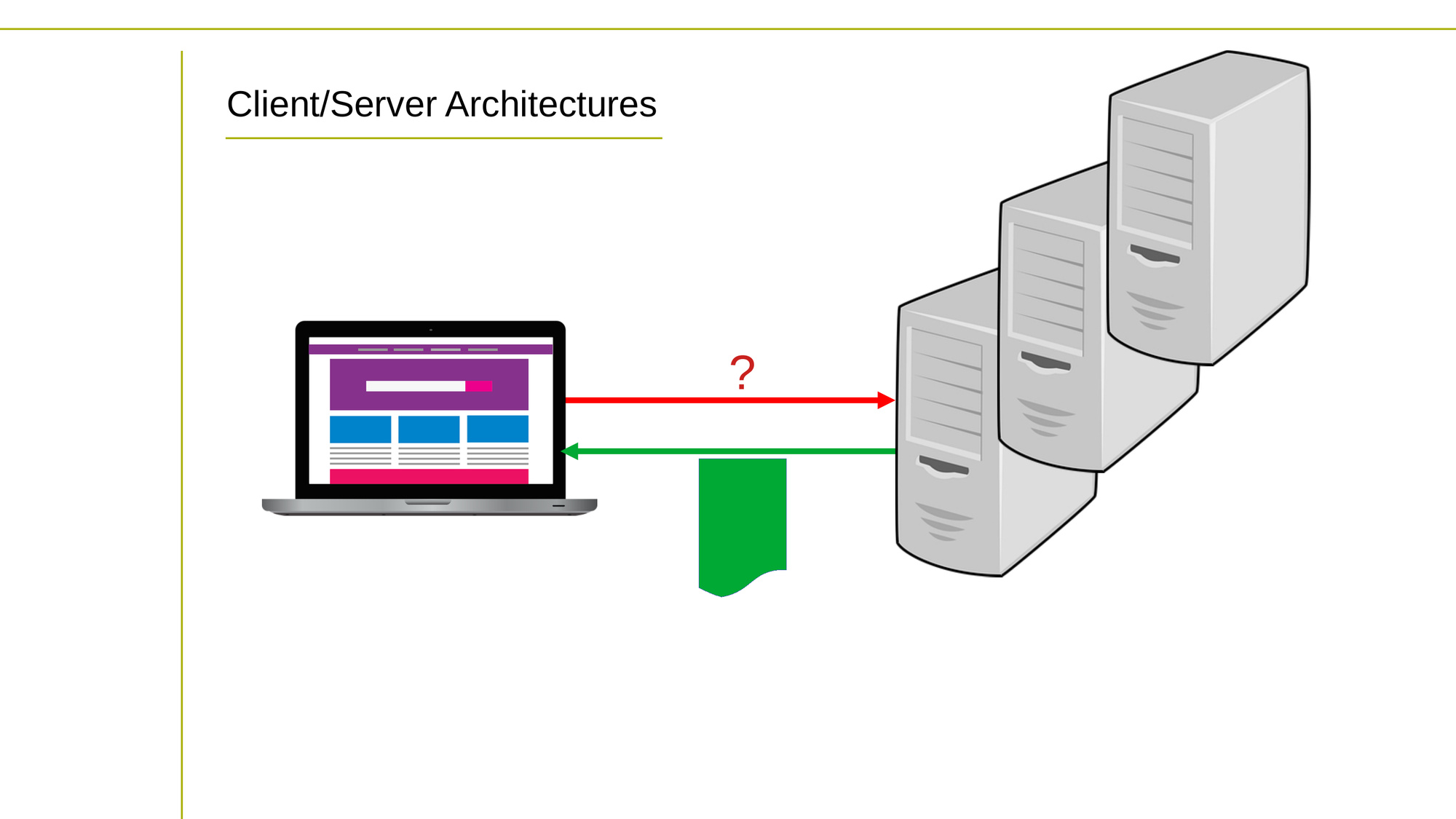
The client/server architecture provides several advantages, including:
- Scalability, meaning that servers can be added or removed from the network as demand changes. This allows the system to scale up or down as needed without having to make changes on the clients.
- Centralization, which means that by centralizing resources on servers, it is easier to manage and control access to those resources, and to enforce security policies.
Examples of client/server applications include email servers, web servers, file servers, and database servers. In each case, the server provides a service or resource that clients can access over a network.
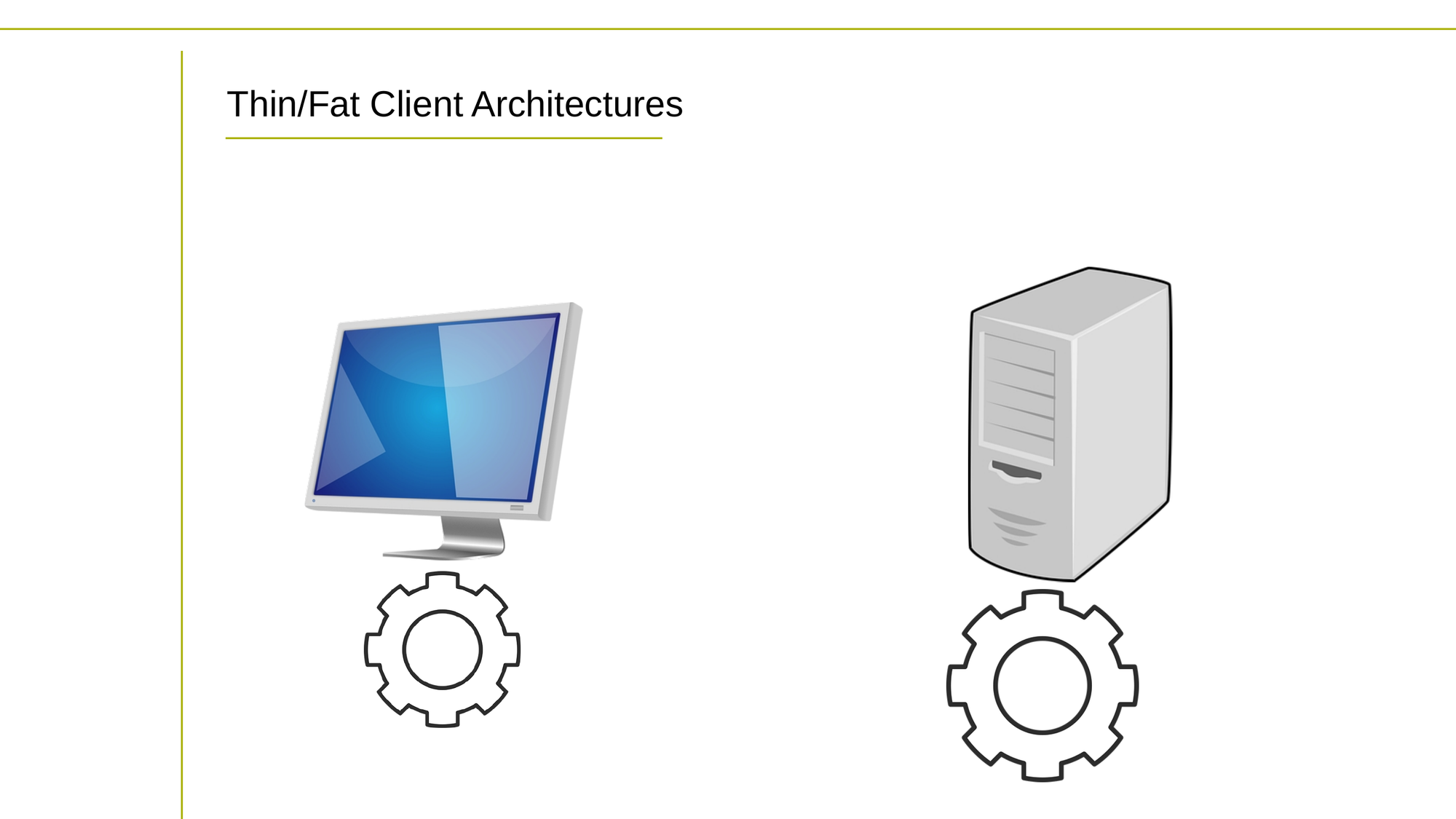
Thin Client and Fat Client Architectures
Thin client and fat client architectures are different approaches to designing client/server computing systems.
In a thin client architecture, the client machine is responsible for only the presentation layer, while the application logic and data processing are handled on the server side. Thin clients typically have limited processing power and memory, and rely heavily on network connectivity to function.
When a user interacts with a thin client, the input is sent over the network to the server, which processes the request and sends back the necessary data to the client for display.
This approach can be more efficient in terms of hardware resources and easier to manage, as the server is responsible for most of the processing and storage. But it can also be more dependent on network connectivity and can suffer from latency issues if the network is slow or unreliable.
Fun fact (or, at least, a relatively fun fact): my very first serious administration project – and my introduction to Linux and network administration – involved deploying thin client infrastructure to save significant costs and efforts. It went well, and launched my admin career.
On the other hand, in a fat client architecture, the client machine is responsible for both the presentation layer and the application logic. The client machine typically has more processing power and memory, and can execute code and process data locally.
This approach can provide better performance and responsiveness, and can be more resilient to network connectivity issues.
When a user interacts with a fat client, the client machine processes the input and executes the necessary code and data processing locally, without relying on the server for every request.
This approach can be more resource-intensive, as the client machine must have sufficient processing power and memory to handle the workload. It can also be more complex to manage, as updates and maintenance must be performed on both the client and server sides.
Microservices vs. Monolith Architectures
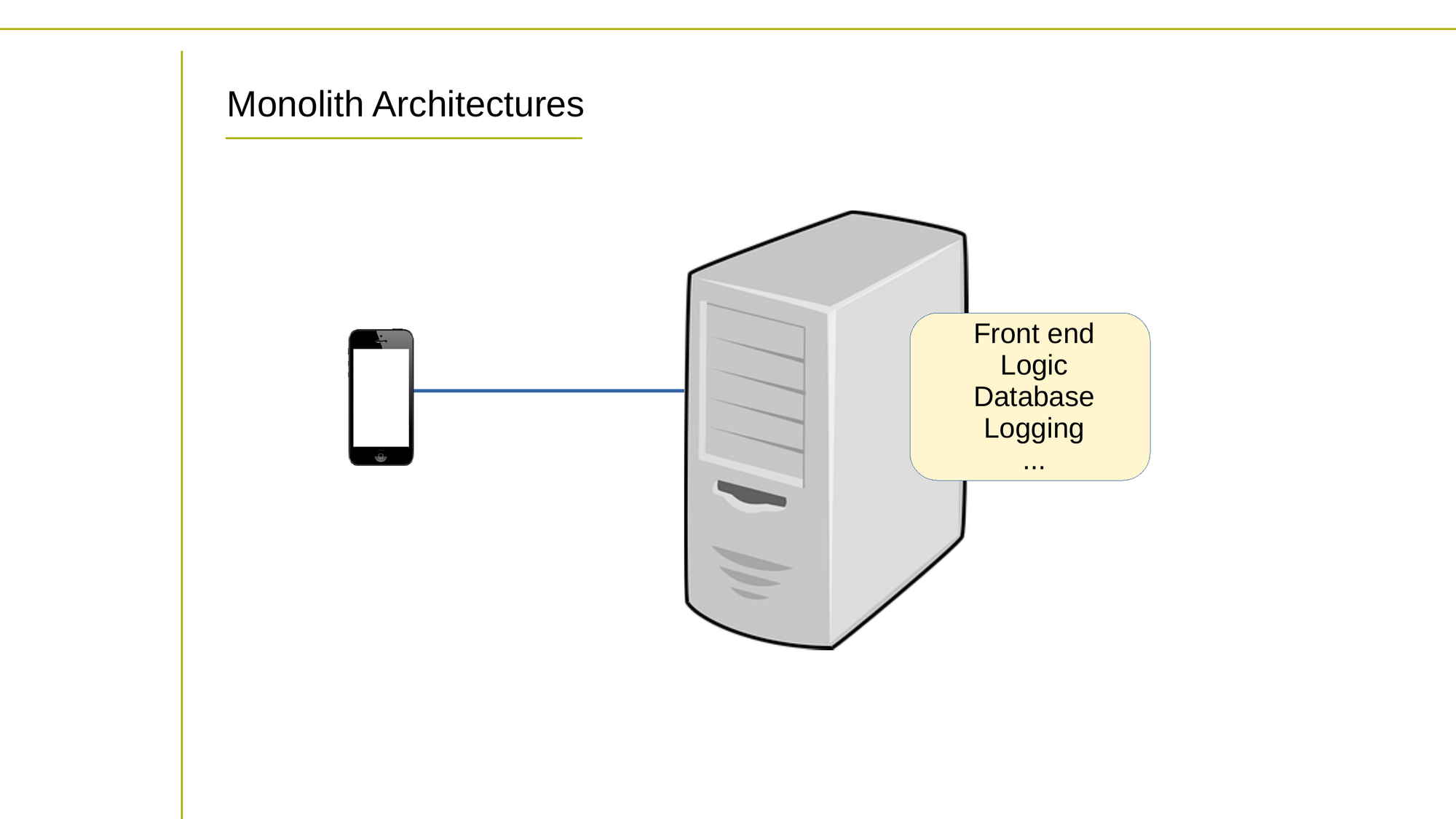
Now, should you design your software as a microservices or monolith architecture? In a monolith architecture, the entire application is built as a single, self-contained unit. All functionality, from data access to user interface, is bundled together in one codebase and deployed as a single unit.
Monoliths are typically easier to develop and deploy, but can become unwieldy and difficult to maintain as the codebase grows in size and complexity.
But in a microservices architecture, the application is divided into smaller, independent services that communicate with each other over a network. Each service is designed to perform a specific task or set of tasks, and can be developed and deployed independently of the other services.
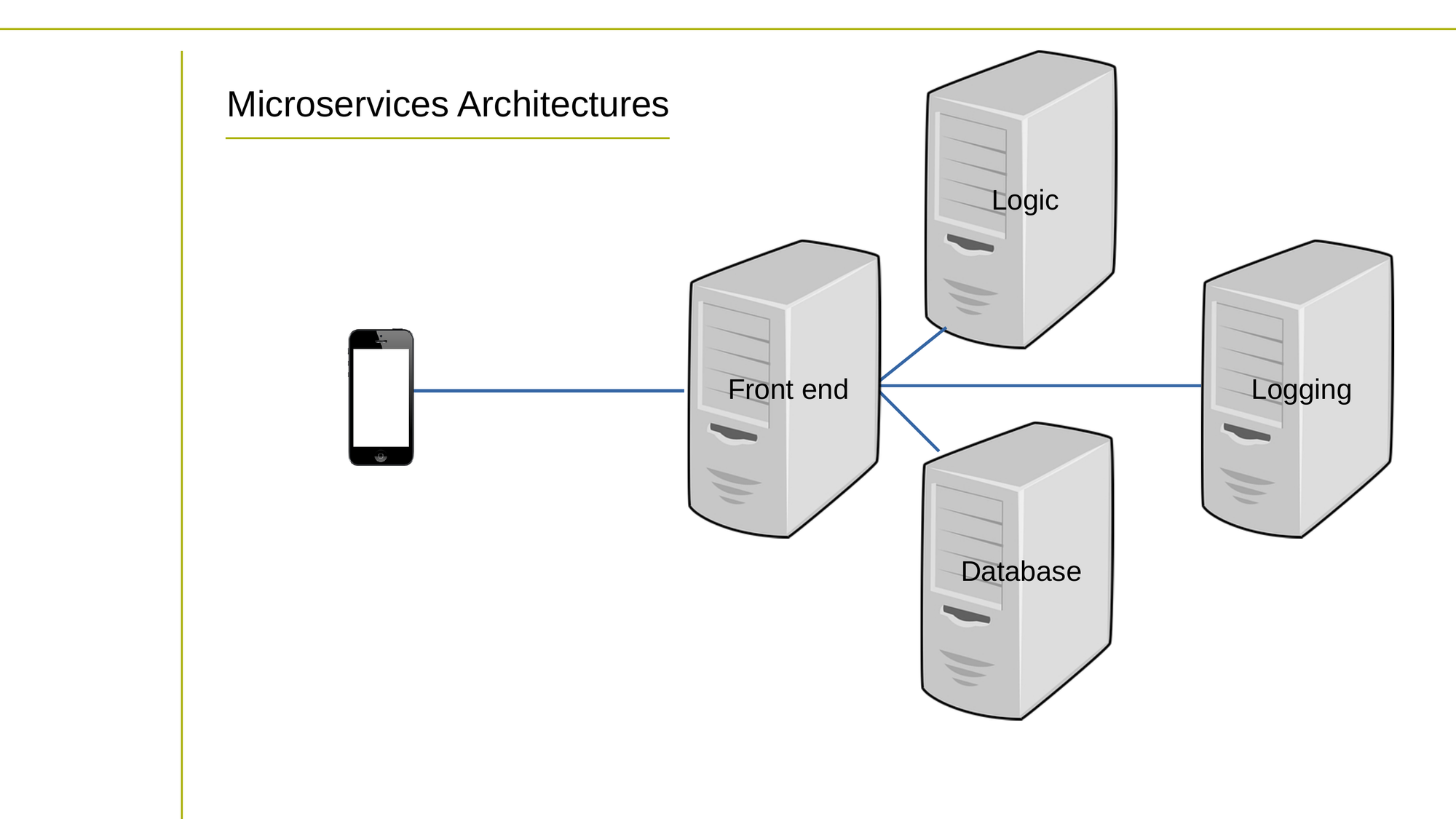
Microservices can be more complex to develop and deploy, but offer greater flexibility and scalability, as each service can be scaled independently to handle changing workloads.
In a monolith architecture, all components of the application are tightly coupled, meaning that changes to one component can have a ripple effect throughout the entire system. This can make it difficult to scale or modify specific components of the application without affecting the entire system.
Microservices architectures, on the other hand, make use of loosely coupled features, meaning that changes to one service have minimal impact on other services. This makes it easier to modify or scale specific components of the application without affecting the entire system.
Web Apps
Web applications are software applications that are accessed through a web browser over a network such as the Internet. The purpose of web applications is to provide users with a convenient and accessible way to perform various tasks and access services over the web.
Web applications can be used for a wide range of purposes, such as e-commerce, online banking, social networking, email, file sharing, and online productivity tools. They can be designed to be accessible from any device with a web browser, including desktop computers, laptops, tablets, and smartphones.
Web applications are typically built using web development technologies such as HTML, CSS, and JavaScript, and can be hosted on a web server that communicates with client-side browsers using various web protocols such as HTTP and HTTPS.
Single Page Applications (SPAs)
An SPA is a web application that loads a single HTML page and dynamically updates the content on that page as the user interacts with it. This is in contrast to traditional web applications, which require a full page refresh every time the user interacts with the application.
In an SPA, the initial HTML, CSS, and JavaScript are downloaded to the client-side browser, and subsequent interactions with the application are handled through asynchronous requests to the server-side API. The server returns data in a lightweight format, such as JSON, which the client-side JavaScript then uses to update the page content without refreshing the entire page.
SPAs are often built using modern JavaScript frameworks and libraries, such as React, Angular, and Vue.js. They offer several benefits over traditional web applications, such as faster load times, improved user experience, and reduced server load. But SPAs can also present some challenges, such as search engine optimization, accessibility, and managing the application state on the client-side.
Application Programming Interfaces (APIs)
An API is a set of rules, protocols, and tools that developers use to build software applications. The purpose of an API is to enable communication and integration between different software applications, allowing them to exchange data and functionality.
Or, in other words, APIs are a tool for securely and efficiently exposing compute functionality and data to public networks. Which is just a different way to bring about a software deployment.
APIs can be classified into several categories, based on their function and level of access:
- Open APIs, also known as public APIs, are accessible to developers outside the organization that owns the API, and often require no authentication or authorization to access.
- Internal APIs, also known as private APIs, are intended for use within an organization and are not accessible to external developers.
- Composite APIs are APIs that combine functionality from multiple APIs into a single interface, simplifying the development process for developers.
- REST APIs are APIs that use the HTTP protocol to access and manipulate data, and are widely used for building web and mobile applications. They make it easy for developers to programmatically expose local resources to remote users in a controlled way. REST stands for Representational State Transfer Application Programming Interface.
- SOAP APIs, where SOAP stands for Simple Object Access Protocol, are APIs that use the SOAP protocol to exchange data between different systems, and are commonly used for enterprise-level applications. These days, SOAP is a much less popular protocol than REST.
Wrapping Up
We’ve worked through some of the most popular software deployment platform alternatives. Now, with a better sense of what’s available, it’s your turn to go out and create!
This article comes from my Complete LPI Open Source Essentials Study Guide course. And there’s much more technology goodness available at bootstrap-it.com
[ad_2]
Source link