
How to Run SQL-Like Queries on Files

[ad_1]
Hello everyone! I’m a Software engineer who is interested in low-level programming, compilers, and tool development.
At the end of 2023, I published my first article on freeCodeCamp about how I created a SQL-like Language to run queries on local Git repositories. If you want a bit more context, give it a read.
At the start of 2024, the project got bigger and bigger with more features and amazing contributors, and I started to think: what if I could run SQL-like queries not only on .git files but on any kind of local and remote data?
In this article, I will take you on a journey of updating the design of the GitQL project to be used also as an SDK. I will also explain how I used it to implement the FileQL project, which is a tool to run the SQL-like query on local files.
The First Use Case for this Idea
My first idea was to be able to use the same features of GitQL to build FileQL, which is a tool that allows you to run queries on a local file system.
Following that, everyone can use the GitQL project as an SDK to build their XQL. For example, LogQL, WeatherQL, CodeQL, AudioQL, BookQL, and so on.
How I Started to Think About the GitQL SDK
The first question was: what can be a different between GitQL and FileQL? This part could be dynamic depending on the data format and how to read them.
The answer was two components. Let’s go over them in the following sections.
The first component is the Data Schema
In each SQL-like query, we need to perform some checks to make sure that everything is valid. For example, in a query like SELECT UPPER(name), commit_count + 1 FROM branches, we need to perform the following checks:
- Check that there is a table with name branches.
- The field
namehas the type of text so it can passed to the functionUPPERwithout any problems. - The field
commit_counthas type the type of integer, so that we can use it with the plus operator and another integer.
These checks can be implemented if we are aware of the table names, field names, and types. This information was static in the GitQL project, but now, when I want to convert it to an SDK, I need to make it dynamic so any SDK user can modify it depending on their own data.
So, I encapsulated all the needed info in a component called DataSchema, and once the user passes it to the SDK, all checks will work correctly.
The second component is the Data Provider
Once we have defined the DataSchema component to make it easier to perform checks on data, we have to move to the next question: how can we provide the data to the GitQL Engine?
In GitQL, we have static functions to provide the data from .git files, but in the SDK, we don’t only work with .git files, and we should support working with any kind of data.
So, the idea is to define an interface between the GitQL Engine and the SDK user to provide any kind of data in the needed format for the Engine. This component is called DataProvider, and I will explain the implementation details in the next section.
The Design and Implementation of the GitQL SDK
The goal is to allow the SDK user to pass their own definition of Data Schema and Provider and integrate them easily with the other GitQL components such as Tokenizer, Parser, Checker, Functions, and Engine.
How to design the Data Schema
The data schema should contain two kinds of information. Firstly, it should define the correct tables and field names, and secondly, it should specify the data types for those fields.
For example, in the case of FileQL, the correct table and field names are:
pub static ref TABLES_FIELDS_NAMES: HashMap<&'static str, Vec<&'static str>> = {
let mut map = HashMap::new();
map.insert(
"files",
vec!["path", "parent", "extension", "is_dir", "is_file", "size"],
);
map
};Here, we define only one table called files, which has six fields: path, parent, extension, is_dir, is_file, and size.
In the other map, we define the correct data type for each field. For example:
pub static ref TABLES_FIELDS_TYPES: HashMap<&'static str, DataType> = {
let mut map = HashMap::new();
map.insert("path", DataType::Text);
map.insert("parent", DataType::Text);
map.insert("extension", DataType::Text);
map.insert("is_dir", DataType::Boolean);
map.insert("is_file", DataType::Boolean);
map.insert("size", DataType::Integer);
map
};Then, we create an instance of Schema, and construct it using the two maps. It should pass them to the Data Schema instance list like this:
let schema = Schema {
tables_fields_names: TABLES_FIELDS_NAMES.to_owned(),
tables_fields_types: TABLES_FIELDS_TYPES.to_owned(),
};How to design the Data Provider
The goal of the Data Provider component is to load the data and map them into the GitQL Engine object structure, so we can define it as an interface with a single function:
pub trait DataProvider {
fn provide(
&self,
env: &mut Environment,
table: &str,
fields_names: &[String],
titles: &[String],
fields_values: &[Box<dyn Expression>],
) -> GitQLObject;
}The SDK user can implement this interface for their own kind of data and make it work with different data.
Also, you can control how many threads you need and what extra parameters you want. For example, in FileQL I implemented it with the name FileDataProvider, and passed the base path to search as parameter.
You can also implement it in any way. For example, APIDataprovider, and load the data from server and map them into GitQLObject. You could also implement is as LogDataProvider, and so on. The main idea is the same – just provide the data to the engine.
How to use the SDK Components together
After adding the GitQL SDK crates to your project and configuring the Data Schema and Provider for your data, we can start using the GitQL SDK:
let mut env = Environment::new(schema);
let query = ...;
let mut reporter = DiagnosticReporter::default();
let tokenizer_result = tokenizer::tokenize(query.to_owned());
let tokens = tokenizer_result.ok().unwrap();
if tokens.is_empty() {
return;
}
let parser_result = parser::parse_gql(tokens, &mut env);
if parser_result.is_err() {
let diagnostic = parser_result.err().unwrap();
reporter.report_diagnostic(&query, *diagnostic);
return;
}
let query_node = parser_result.ok().unwrap();
let provider: Box<dyn DataProvider> = Box::new(FileDataProvider::new(base_path.to_owned()));
let evaluation_result = engine::evaluate(&mut env, &provider, query_node);The code above takes the query as a string and processes it until getting the evaluation result from the engine:
- Create an Environment instance using the
DataSchemato track types. - Create an instance of
DiagnosticEngineto use it for error reporting. - Pass the query to the tokenizer to convert the string into a list of tokens.
- Pass the list of tokens to the parser to convert it to
TreeDataStructure. - Create an instance of your
DataProviderand pass it with the tree to the engine. - The engine returns the evaluation result which is an error or data.
Those components are not new at all, besides Data Schema and Provider, and you can enjoy reading about the design and implementation details in the first article.
This is almost all you need to make the project work, but you can add more customization and extra components, such as CLI arguments. The final result will be like this:
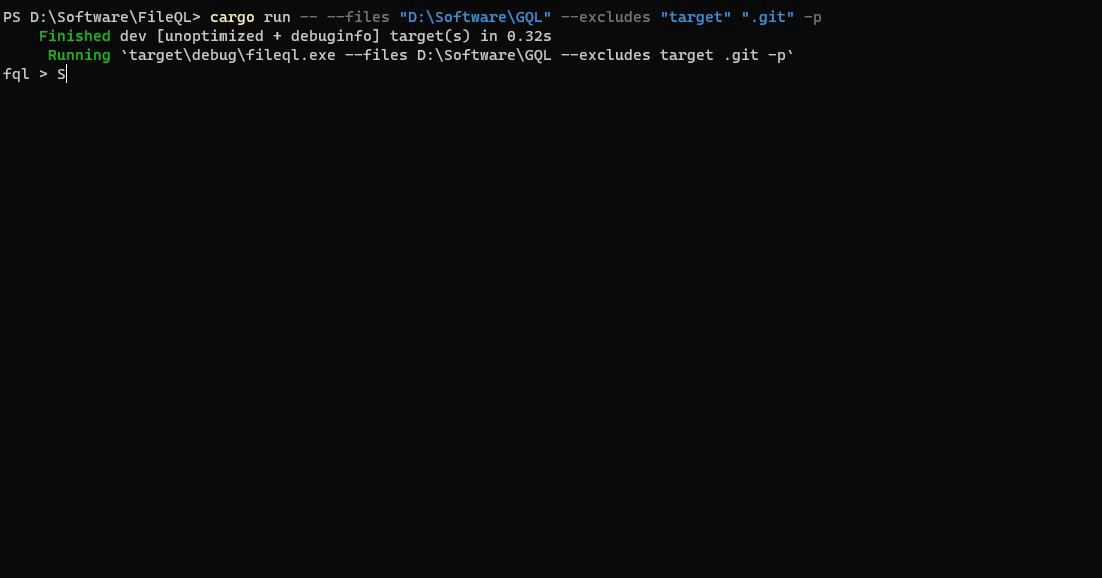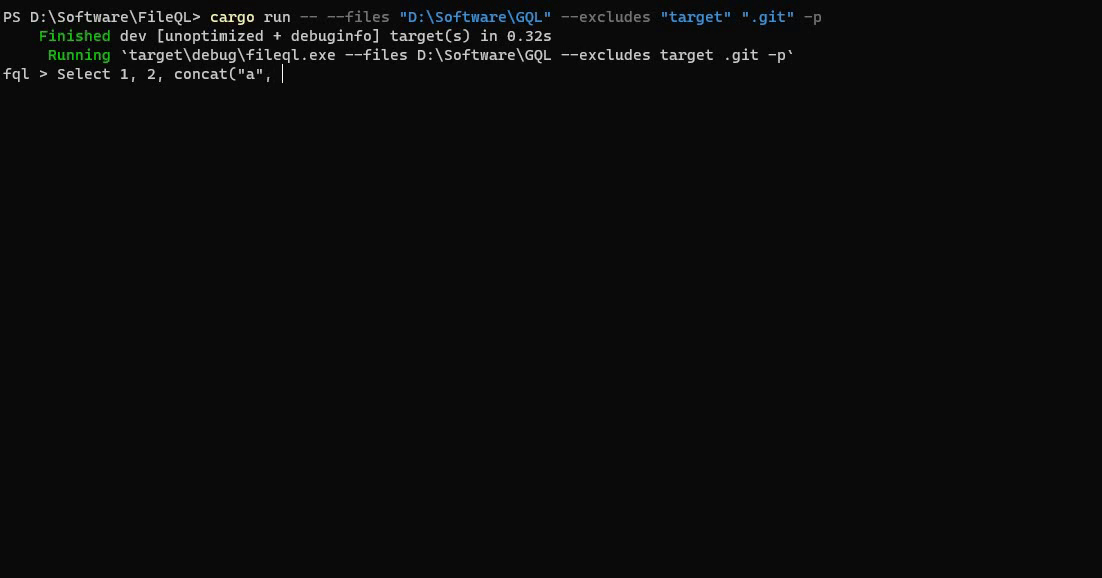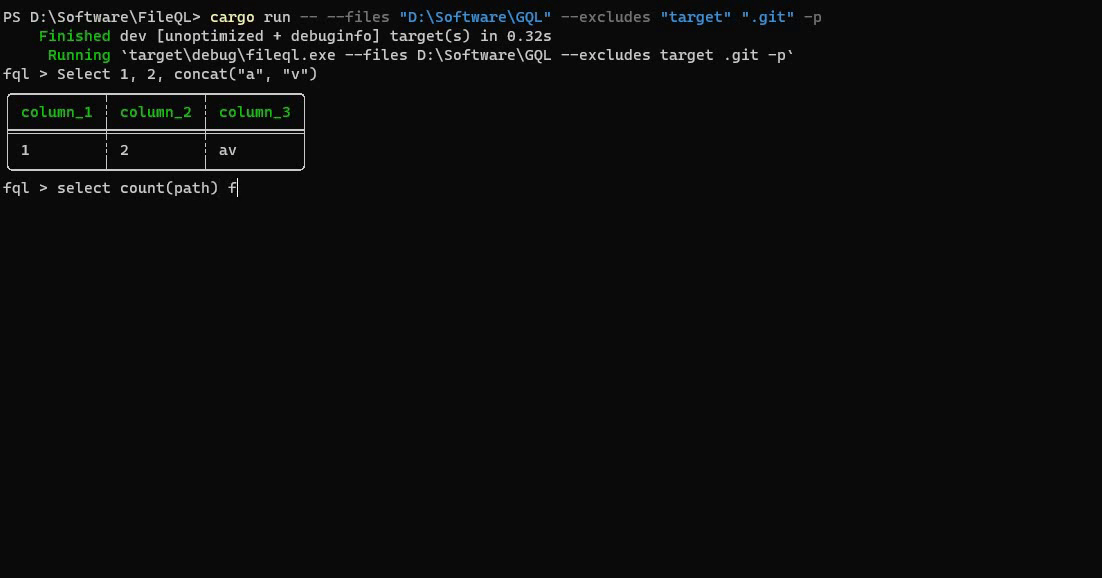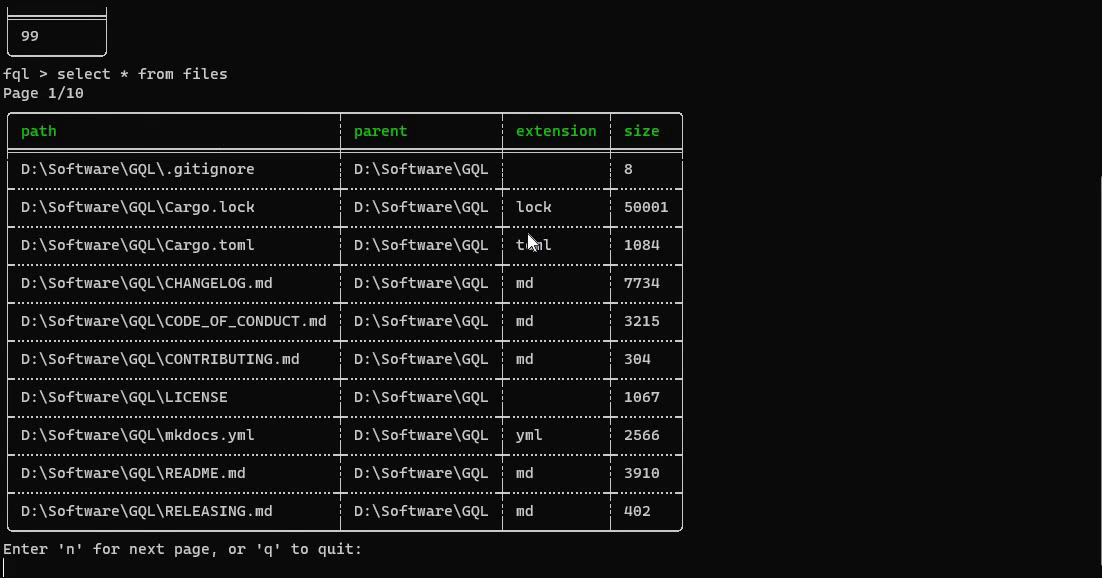
You can find the full source code with all customizations in the FileQL repository.
Conclusion
You can check the FileQL project as a full sample created only in three files.
If you liked the project, you could give it a star ⭐ on GitQL and FileQL
You can check the website for how to download and use the project on different operating systems.
The project is not done yet – this is just the start. Everyone is welcome to join and contribute to the project and suggest ideas or report bugs.
Thanks for reading!
[ad_2]
Source link